这一节主要讲感知 (Perception)
1. 视觉通道 (Visual Channel): 形状、颜色、运动等等
视觉通道有时被分离,有时被整合。
分离: 我们能独立地判断两个不同的视觉通道。
整合: 两个相同的视觉通道会被当作一个整体来看待。
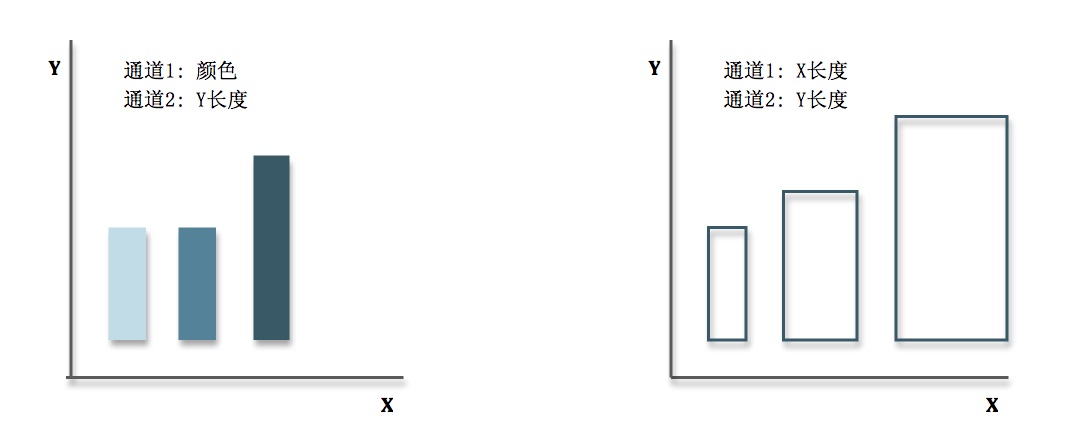
例一: 左边的小柱子由颜色和长度两个不同的视觉通道构成,可以清晰地分辨出两个纬度上的变化,而右边的小柱子都是由长度构成,所以人们更倾向于将它们合并成面积而描述它们“变大了。”
例二: 下面的地图很多人认为是一个不太成功的作品,包括给我上这堂课的Hanspeter Pfister 教授。这组地图用美国人口普查数据来研究美国是否最富有的人享受了最好的教育。最左边的三幅小地图分别显示了:
红色: 阅读成绩的分布,颜色越深的地区成绩越好
黄色: 写作成绩的分布,颜色越深的地区成绩越好
蓝色: 收入分布,颜色越深的地区收入越高
接下来,把这三副地区重叠在一起,我们能得出一个直观的结论: 颜色深的地方一定是收入和成绩都好的地区,颜色浅的地方收入比较低成绩也不太好。作者用了同一个视觉通道--颜色的变化来描述三个变量,最终读者只能把三个变量当作一个整体来判断,而对于变量之间的相互影响却很难察觉。当然对色彩知识有深入了解的同学也许可以得出深刻的结论:红黄蓝三种颜色各自从深到浅为4层,排列组合有4X4X4=64种结果,那么你绝对需要另一张表格来解释这64种颜色分别代表了什么意思,还不算这64种颜色中大部分是极为相近的。所以无辜的观众第一眼看上去只可能以为是屏幕分辨率出了问题。

2.如何突显重要的事物
并不是每一个视觉通道都能突显重要的事物。下面的例子就告诉我们颜色比形状更容易区别。

3.视觉变量理论 - Jacques Bertin
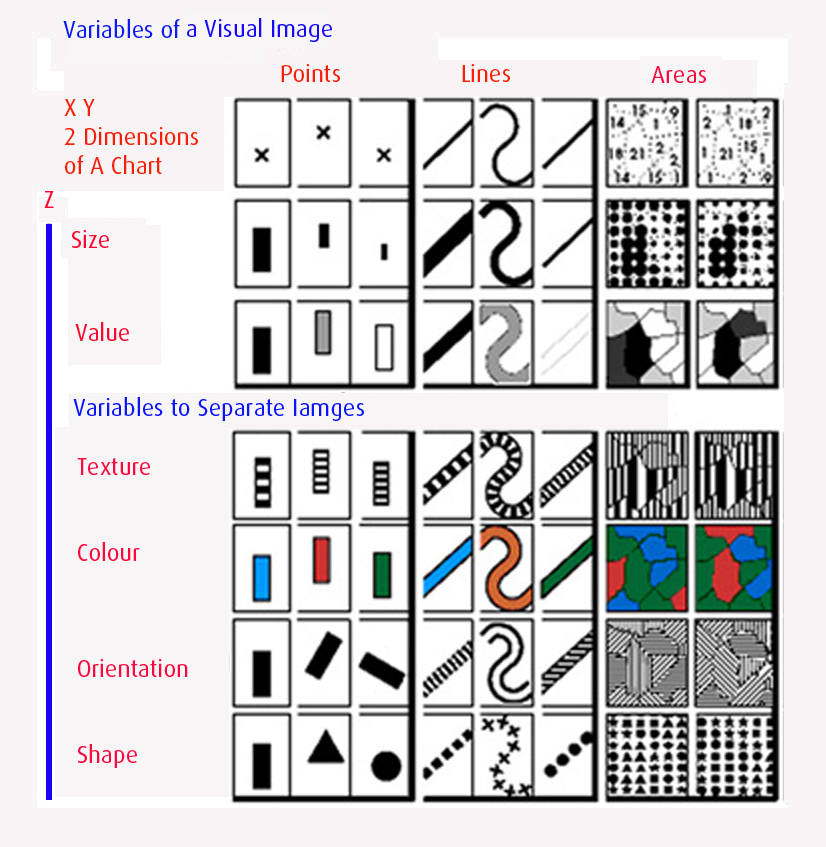
Bertin是法国制图和符号学的专家,在1967年提出了视觉变量理论,要点见下图。我的理解如下 (欢迎讨论):
三种符号: (顶端横轴从左至右)点、线、面
视觉通道: (左端纵轴从上至下)位置、长度、亮暗、纹理、颜色、角度、形状。其中,除了位置是由x和y两个维度确定的,其余都属于第三维度
这样一个3X7矩阵向我们展示了这三种基本符号如何随着不同的视觉通道而变化,因此也能帮助找到对于不同的符号,哪一种视觉通道是最有效的
4.数据类型和视觉通道
基本数据类型有四种: 名义变量(categorical,比如男女)、序数变量(ordinal,比如大中小)、等距变量(interval,比如5摄氏度、1982年)和比率变量(ratio,一般的数字度量比如2米、5千克)。
1967年,Bertin给出了他关于不同数据类型在不同视觉通道中有效性的意见(见下图)。注: 等距变量如果基点确定的话和比率变量很相似,所以两者归并为数量变量(Quantitative)来论。
| 名义变量 | 序数变量 | 数量变量 | |
|---|---|---|---|
| 位置 | √ | √ | √ |
| 长度 | √ | √ | √ |
| 亮暗 | √ | √ | ~ |
| 纹理 | √ | ~ | x |
| 颜色 | √ | ~ | x |
| 角度 | √ | x | x |
| 形状 | √ | x | x |
√ = Good, ~ = Ok, x = Bad
这里我们可以看出,对于我们经常接触的数量变量,比较有效的呈现方式是位置和长度,人对位置和长度变化的估计比其他方式更准确。1984年Cleveland和McGill的一项实验就向我们证明了我们平时大量使用的饼图(pie chart),其实并不比柱状图(Bar Graph)更有效。

5."看"和"看见"
人的注意力都是有选择性的。由于视觉产生的生理机制,观察也许从不会“客观”。个体大部分视觉信息是观察的总结,往往缺乏细节,而处理某一特征的注意力通常抑制处理其他特征,所以这更要求我们一定要突出重要的信息。
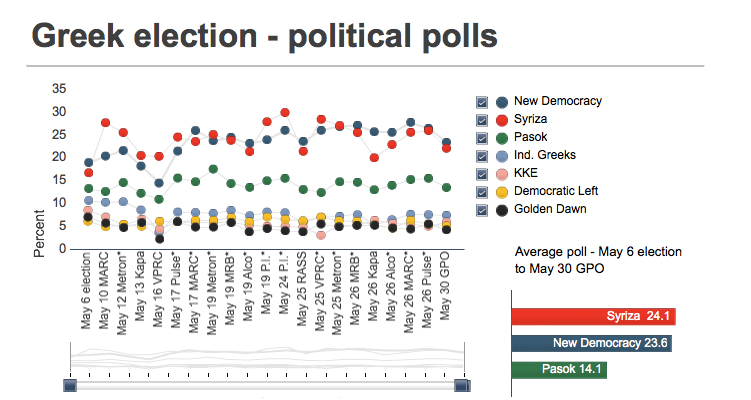
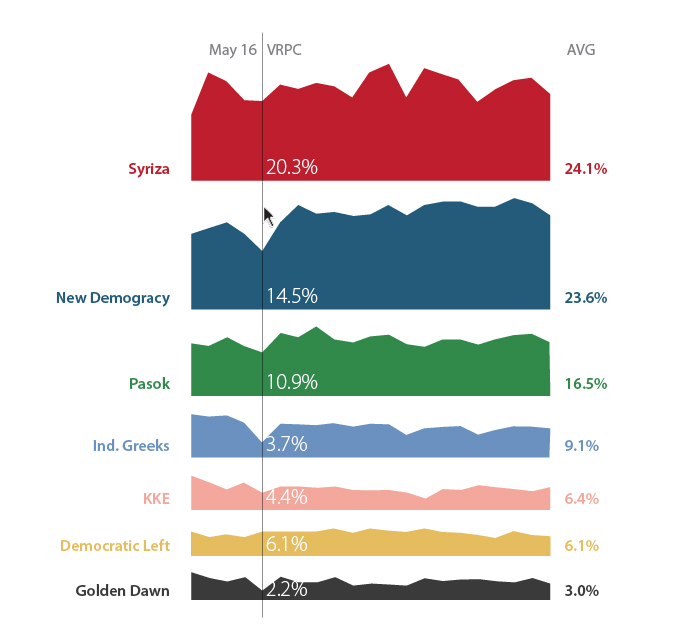
Bryan Connor在The Why Axis中有一篇批评路透社关于希腊政党选举数据图的文章。我截来图供大家吐槽,原文链接在这里。图一是路透社的设计,图二是重新设计,高下立断。
这节的最后还是附上扩展阅读和其豆瓣链接
Tags: DataVis